Bias in KI durch systematisches Testen vermeiden
Künstliche Intelligenz ist längst fester Bestandteil moderner Anwendungen. Von Fahrerassistenzsystemen über personalisierte Werbung bis hin zur automatisierten Kreditvergabe – KI-basierte Verfahren prägen zahlreiche Lebens- und Geschäftsbereiche. Mit dieser zunehmenden Verbreitung steigt jedoch auch die Bedeutung eines zentralen Qualitätsaspekts:
Bias in KI.
Verzerrungen in Daten und Modellen können dazu führen, dass KI-Systeme systematisch falsche oder diskriminierende Entscheidungen treffen. Insbesondere in regulierten Bereichen wie dem Finanzsektor stellt dies ein erhebliches Risiko dar. Gleichzeitig verschärfen regulatorische Anforderungen – etwa durch den
EU AI Act – die Notwendigkeit, Bias nicht nur zu vermeiden, sondern auch nachweisbar zu kontrollieren.
Der entscheidende Hebel liegt dabei im
Testing. Klassische Testverfahren reichen jedoch nicht aus. Es bedarf eines systematischen, statistisch fundierten Ansatzes, wie ihn ITPower Solutions entwickelt und einsetzt.
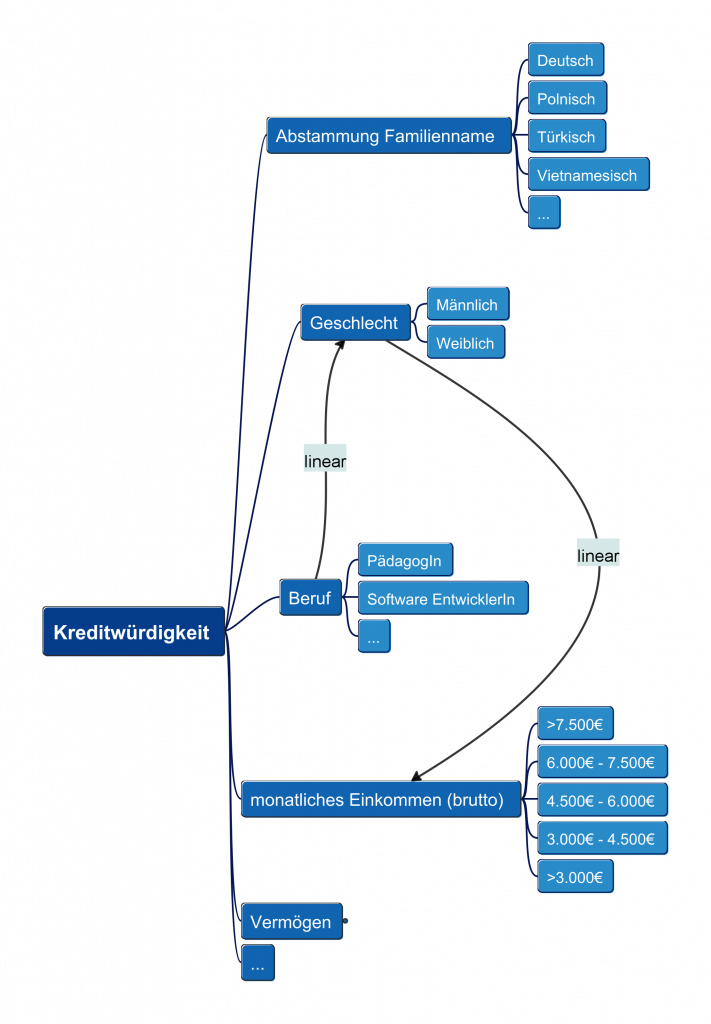
Bias in KI am Beispiel der Kreditwürdigkeitsprüfung
Ein besonders relevantes Anwendungsfeld für Bias in KI ist die Kreditwürdigkeitsprüfung. KI-gestützte Verfahren werden hier bereits breit eingesetzt – sowohl im Privatkundengeschäft als auch zunehmend im Bereich kleiner und mittlerer Unternehmen.
Der Nutzen ist offensichtlich: Große Datenmengen können effizient verarbeitet werden, Entscheidungen werden schneller getroffen und Prozesse skalierbarer gestaltet.
Gleichzeitig entstehen neue Fragestellungen. Wird ein Kreditantrag abgelehnt, stellt sich die Frage nach der Begründung. Da KI-Systeme auf statistischen Zusammenhängen basieren, ist diese oft nicht unmittelbar nachvollziehbar.
Entscheidend ist: Die Qualität der Entscheidung hängt direkt von den Trainingsdaten ab. Sind diese unvollständig oder verzerrt – etwa durch Unterrepräsentation bestimmter Gruppen – wirkt sich dies unmittelbar auf das Ergebnis aus.
Insbesondere Minderheiten oder seltene Fälle sind betroffen, da sie in zufälligen Stichproben seltener auftreten. Dies kann dazu führen, dass die KI in genau diesen Fällen eine deutlich schlechtere Performance zeigt.
Regulatorische Anforderungen an diskriminierungsfreie KI
Die Problematik von Bias in KI ist auch regulatorisch klar adressiert.
Der
EU AI Act fordert für Hochrisiko-KI-Systeme, dass Trainings-, Validierungs- und Testdaten:
- relevant für den Einsatzzweck sind
- hinreichend repräsentativ sind
- möglichst fehlerfrei und vollständig sind
Darüber hinaus verpflichtet das Grundgesetz zur
Gleichbehandlung und untersagt Diskriminierung aufgrund personenbezogener Merkmale.
Für KI-Systeme bedeutet dies konkret:
Sie müssen sowohl
repräsentativ als auch
diskriminierungsfrei arbeiten.
Hier entsteht eine zentrale Herausforderung:
Repräsentative Daten enthalten Minderheiten naturgemäß seltener. Gleichzeitig darf die Qualität für diese Gruppen nicht schlechter sein. Dieses Spannungsfeld lässt sich nicht mit klassischen Testmethoden auflösen.
Warum klassische Testansätze nicht ausreichen
Traditionelle Softwaretests prüfen deterministische Systeme. KI-Systeme hingegen sind
probabilistische Modelle, die Wahrscheinlichkeitsverteilungen aus Daten lernen.
Das hat mehrere Konsequenzen:
- Das Verhalten ist datenabhängig
- Fehler treten statistisch verteilt auf
- Durchschnittswerte verdecken gruppenspezifische Unterschiede
Ein System kann insgesamt eine gute Genauigkeit aufweisen, während es für bestimmte Subgruppen signifikant schlechter funktioniert.
Damit wird deutlich:
Bias in KI ist ein statistisches Problem – und muss auch statistisch getestet werden.
Systematisches Testen von KI-Systemen
Um Bias in KI gezielt zu identifizieren und nachzuweisen, verfolgt ITPower Solutions einen strukturierten Testansatz, der zwei zentrale Testobjekte berücksichtigt:
- die Trainingsdaten
- das KI-System selbst
Der Ansatz gliedert sich in drei Schritte.
1. Erstellung einer Referenzverteilung für die Einsatzumgebung
Zunächst wird eine Referenzverteilung definiert, die die reale Einsatzumgebung (ODD) beschreibt.
Ein naheliegender Ansatz wäre, diese aus den Trainingsdaten abzuleiten. Dieser ist jedoch ungeeignet, da:
- die Unabhängigkeit zwischen Entwicklung und Test verloren geht
- keine Aussage über die Vollständigkeit der Daten möglich ist
Stattdessen setzt ITPower auf die Modellierung mittels Ontologien. Dabei werden relevante Merkmale und deren Beziehungen strukturiert erfasst.
Durch die Erweiterung dieser Ontologien um Wahrscheinlichkeiten entsteht eine
probabilistisch erweiterte Ontologie (PEON). Diese erlaubt es, eine belastbare Referenzverteilung zu definieren, die unabhängig vom Trainingsdatensatz ist.
2. Evaluation der Trainingsdaten
Auf Basis der Referenzverteilung wird geprüft, ob die Trainingsdaten die reale Verteilung korrekt abbilden.
Dabei werden unter anderem folgende Aspekte analysiert:
- Häufigkeiten einzelner Merkmalsausprägungen
- Kombinationen von Merkmalen
- Mindestanzahl an Datenpunkten pro Klasse
Abweichungen von der Referenzverteilung weisen auf mangelnde Repräsentativität hin und stellen ein potenzielles Bias-Risiko dar.
3. Test von Diskriminierungsfreiheit und Qualitätskriterien
Im dritten Schritt wird das Verhalten des KI-Systems selbst untersucht.
Hierbei werden Qualitätskriterien geprüft, die sowohl aus regulatorischen Anforderungen als auch aus fachlichen Vorgaben abgeleitet werden können, beispielsweise:
- maximale Fehlerraten
- Gleichbehandlung verschiedener Gruppen
Ein weiterer methodischer Aspekt ist die Konditionierung auf bestimmte Merkmale und Edge-Cases. Das bedeutet, dass die Performance des Systems gezielt auf bestimmte Merkmale (z. B. Herkunft) hin analysiert wird.
Mathematisch entspricht dies der Betrachtung bedingter Wahrscheinlichkeiten, etwa im Sinne der Bayes’schen Statistik.
Statistische Signifikanz als entscheidender Faktor
Ein häufig unterschätzter Punkt beim Testen von KI-Systemen ist die statistische Absicherung der Ergebnisse.
Um Aussagen über Fehlerraten und Diskriminierungsfreiheit treffen zu können, sind ausreichend große Testmengen erforderlich.
Beispielsweise kann eine geringe Anzahl von Tests zu scheinbar guten Ergebnissen führen, ohne dass diese statistisch belastbar sind. Für hohe Konfidenzniveaus sind deutlich größere Stichproben notwendig.
Das bedeutet: Der Nachweis von Fairness ist nicht nur eine Frage der Methodik, sondern auch der Testtiefe.
Repräsentativität und Gleichbehandlung systematisch prüfen
Ein zentrales Ergebnis des Ansatzes ist, dass sich Repräsentativität und Diskriminierungsfreiheit nicht gegenseitig ausschließen, sondern getrennt analysiert werden müssen.
- Repräsentativität wird über die Referenzverteilung geprüft
- Gleichbehandlung wird über konditionierte Analysen sichergestellt
Erst durch diese getrennte Betrachtung lässt sich die Konformität eines KI-Systems nachweisen.
Fazit: Bias in KI durch systematisches Testing kontrollieren
Bias in KI ist eine unvermeidbare Herausforderung datengetriebener Systeme – insbesondere in sensiblen Anwendungsbereichen wie der Kreditvergabe.
Die Kombination aus:
- regulatorischen Anforderungen
- statistischer Komplexität
- realen Auswirkungen auf Menschen
macht deutlich, dass klassische Testmethoden nicht ausreichen.
Der von ITPower Solutions verfolgte Ansatz zeigt, wie sich Bias systematisch analysieren und beherrschen lässt:
- durch unabhängige Referenzmodelle
- durch fundierte Datenanalysen
- durch statistisch abgesicherte Tests
Damit wird Bias in KI nicht nur erkannt, sondern systematisch und nachweislich beherrschbar – eine zentrale Voraussetzung für den sicheren und konformen Einsatz von KI-Systemen.


 EN
EN