Sprachen

Künstliche Intelligenz verändert Branchen und Geschäftsmodelle – und verbraucht dabei eine wachsende Menge an Energie. KI-Systeme beanspruchen heute bereits rund ein Prozent des weltweiten Stromverbrauchs, mit steigender Tendenz. Damit rückt eine Frage in den Mittelpunkt, die für Unternehmen zunehmend strategisch relevant wird: Wie lassen sich leistungsfähige KI-Anwendungen wirtschaftlich und ressourcenschonend betreiben?
Das Projekt KERE – Worum geht es?
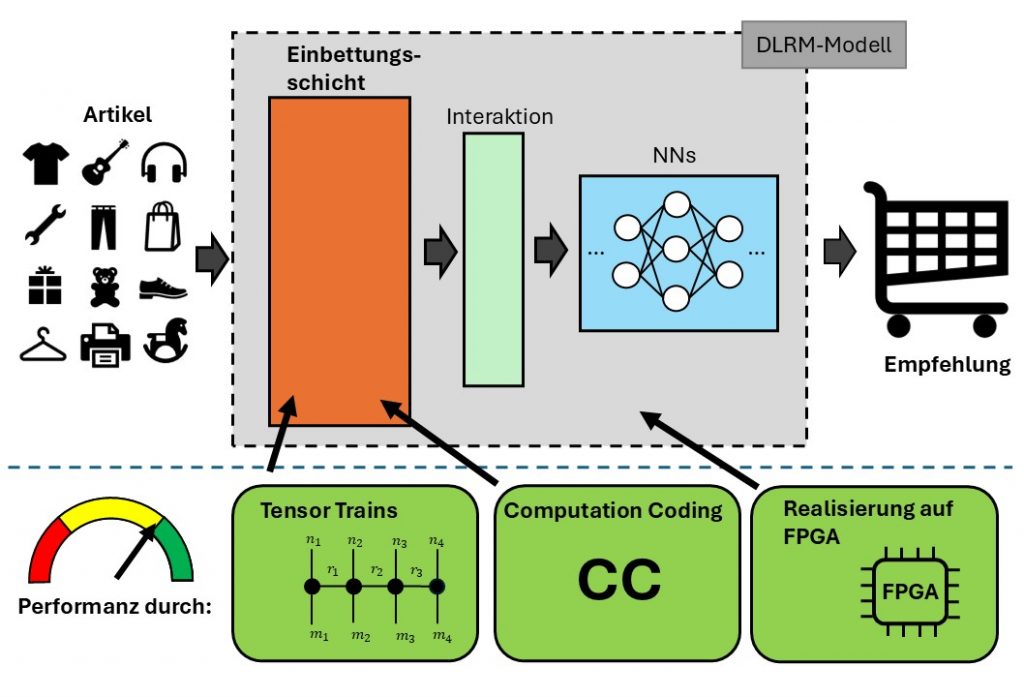
KERE („Kosten- und energieeffiziente Realisierung von Empfehlungssystemen“) ist ein gemeinsames Forschungsprojekt von ITPower Solutions und der Universität Rostock, mit der GK Artificial Intelligence for Retail AG als assoziiertem Partner. Das Projekt läuft im Rahmen des Föderprogramms KMU-innovativ, finanziert vom Bundesministerium für Forschung, Technologie und Raumfahrt (BMFTR). Im Fokus stehen KI-basierte Empfehlungssysteme, genauer Deep Learning Recommendation Models (DLRMs). Diese Modelle entscheiden in Onlineshops, Streaming-Plattformen oder digitalen Marktplätzen darüber, welche Inhalte oder Produkte Nutzern als Nächstes vorgeschlagen werden.
Diese Systeme sind heute unverzichtbar – aber auch teuer im Betrieb. Bei einem typischen Empfehlungssystem mit täglichen Anfragen in zweistelliger Millionenhöhe, betragen die Kosten für die Cloud-Ressourcen über 100.000 Euro jährlich. Der Grund liegt in ihrer Architektur: Um Nutzerverhalten und große Produktkataloge abzubilden, benötigen sie sehr viel Speicher und Rechenleistung. Das führt zu hohen Infrastrukturkosten und einem entsprechend hohen Energieverbrauch.
KERE verfolgt ein ganzheitliches Konzept und ruht auf drei Ansätzen, die ineinandergreifen.
Der erste Ansatz reduziert den Speicherbedarf durch eine sogenannte Tensor-Train-Zerlegung. Dabei werden die speicherintensiven Einbettungs-Matrizen, die einen Großteil der Parameter beinhalten und mehrere Millionen Zeilen enthalten können, durch eine „Kette“ kleinerer Tensoren ersetzt. Aufbauend auf dem Facebook-Ansatz TT-Rec bestimmt KERE die optimalen Zerlegungsparameter automatisch per Clusteranalyse, um möglichst viele Parameter einzusparen und dabei möglichst viel Information zu erhalten. Dadurch sinkt der Speicher- und Rechenbedarf bereits auf der grundlegenden Systemebene. In ersten Tests konnte die Parameteranzahl auf einen Bruchteil des Originalwerts reduziert werden.
Der zweite Ansatz zielt auf das Training der KI-Modelle. Hier geht es darum, Lernprozesse effizienter zu gestalten, sodass weniger Rechenschritte notwendig sind, um ein leistungsfähiges Modell zu erzeugen. Statt klassischer Verfahren wird ein spezialisierter Trainingsansatz mittels eines Riemannschen Stochastischen Gradientenabstieg verwendet (Riemannian SGD). Im Gegensatz zum klassischen Stochastischen Gradientenabstieg (SGD) nutzt man dabei die mathematische Struktur der Tensor-Trains und führt die Optimierung auf einem Teilraum durch, einer sogenannten Mannigfaltigkeit. Dadurch kann das Modell in weniger Schritten optimiert werden. Das spart Zeit, Energie und Kosten.
Der dritte Ansatz soll ein angelerntes Modell effizient auf dedizierter Hardware umsetzen. Die Universität Rostock wird das Computation-Coding Verfahren auf die Tensor-Trains anwenden. Dabei werden Matrizen in Teilmatrizen mit Zweierpotenzen zerlegt. Dadurch lassen sich aufwendige Matrixmultiplikationen durch Bitshifts effizient in Hardwareoperationen umsetzen. Dafür eignen sich FPGAs (Field Programmable Gate Arrays) besonders gut. Diese elektronischen Schaltungen lassen sich flexibel an die Anforderungen des Modells anpassen und arbeiten wesentlich energieeffizienter als klassische Cloud-Infrastrukturen. Das Ergebnis ist ein geringerer Stromverbrauch im laufenden Betrieb und perspektivisch mehr Unabhängigkeit von teuren Cloud-Ressourcen. Ziel ist es, das komplette Modell auf einem FPGA zu implementieren. Die Übertragung von Computation Coding auf Tensor-Train-Arithmetik ist dabei eine wissenschaftliche Neuheit – ebenso wie die angestrebte vollständige FPGA-Umsetzung eines Empfehlungssystems bisher noch nirgends realisiert wurde.
Für Unternehmen, die KI-basierte Empfehlungssysteme einsetzen, sollen durch die Ergebnisse unmittelbare wirtschaftliche Vorteile realisiert werden. Durch die Reduktion von Speicherbedarf, Rechenaufwand und Energieverbrauch können die Betriebskosten solcher Systeme signifikant gesenkt werden. Gleichzeitig eröffnet sich eine neue Perspektive: KI-Anwendungen könnten künftig stärker auf spezialisierter, eigener Infrastruktur betrieben werden – mit mehr Kontrolle über Kosten, Daten und Performance.
Ein weiterer wichtiger Aspekt: Effizienzsteigerungen und Kostensenkungen können leistungsfähige Systeme auch für kleine und mittlere Unternehmen (KMU) zugänglich machen. Denkbar sind Anwendungsszenarien sowohl für Nutzer als auch als Anbieter von KI-gestützten Empfehlungssystemen in den Bereichen E-Commerce, Social Media oder Streaming. Damit trägt das Projekt dazu bei, den Einsatz von KI breiter in der Wirtschaft zu verankern.
KERE läuft bis Mitte 2027 und befindet sich aktuell in der Umsetzungsphase. Wenn Sie mehr über das Projekt erfahren oder sich über konkrete Anwendungsfälle austauschen möchten, sprechen Sie uns gerne an. Wir stehen für eine Diskussion und Beratungsgespräche rund um das Thema künstliche Intelligenz gerne zur Verfügung!

Ich berate Sie gerne zu allen Fragen rund um unsere Forschungsaktivitäten, Dienstleistungen und Produkte! Melden Sie sich oder vereinbaren Sie einfach einen Termin für ein kostenloses Beratungsgespräch.
Dr. Sadegh Sadeghipour
E-Mail: sadegh.sadeghipour@itpower.de
Telefon: +49 (0)30 6098501-11
 EN
EN